SimpleDev
Web Dev Person / Ex Performance ECU Calibrations Person
- 3 Posts
- 5 Comments


 10·5 months ago
10·5 months agoI haven’t personally tried it yet with Ollama but it should work since it looks like Ollama has the ability to use OpenAI Response Formatted API https://github.com/ollama/ollama/blob/main/docs/openai.md
I might give it go here in a bit to test and confirm.
Local models are indeed already supported! In fact any API (local or otherwise) that uses the OpenAI response format (which is the standard) will work.
So you can use something like LM Studio to host a model locally and connect to it via the local API it spins up.
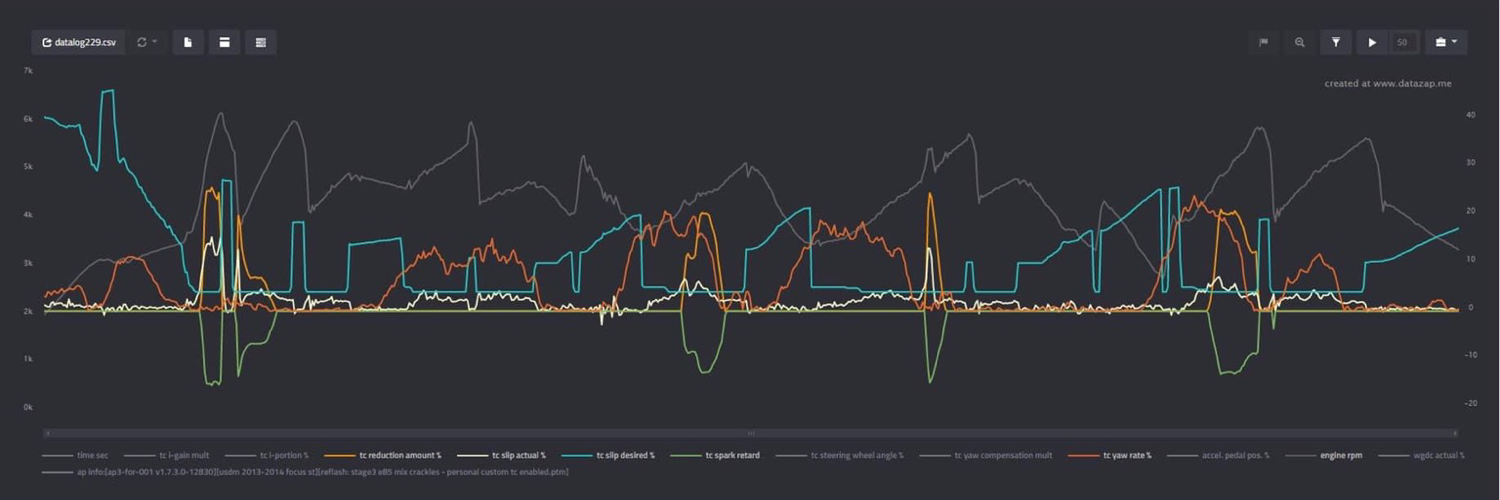
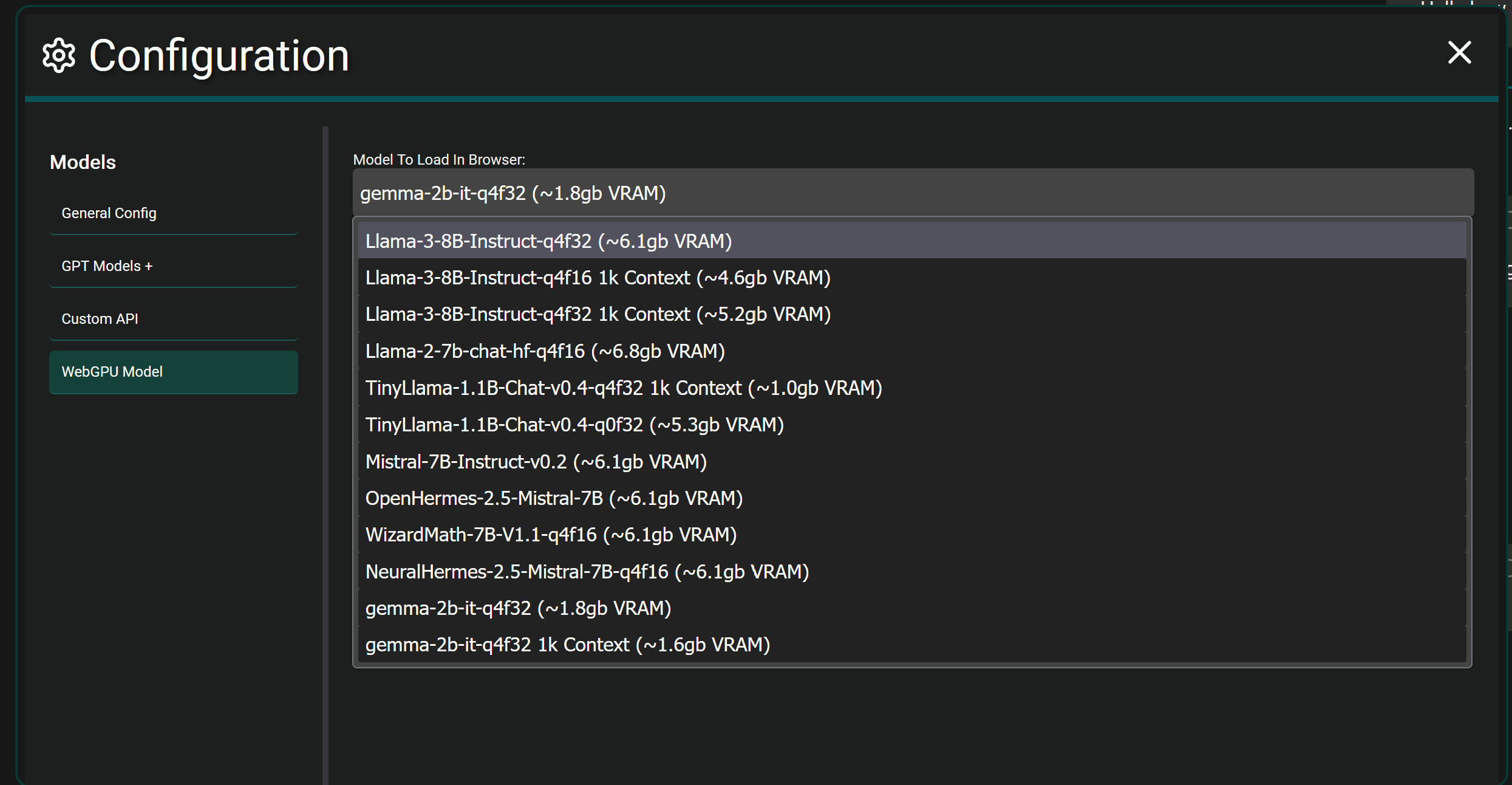
If you want to get crazy…fully local browser models are also supported in Chrome and Edge currently. It will download the selected model fully and load it into the WebGPU of your browser and let you chat. It’s more experimental and takes actual hardware power since you’re fully hosting a model in your browser itself. As seen below.

 2·1 year ago
2·1 year agoInteresting, thanks for the info!
I wasn’t aware of the update process being used as an attack vector (if it’s still a thing) gonna have to read up more on that.
I used Apple for the last few years until recently and I can’t say I’ve ever really noticed stuff like apps faking being another app. That’s not to say it doesn’t happen of course.
I do know the Apple app approval process is definitely more strict than what is required for the Play Store.
I’m not very experienced with Apple or Android development so I’d be curious to hear from devs that use both platforms as well.

{kind=link}
This project is entirely web based using Vue 3, it doesn’t use langchain and I haven’t looked into it before honestly but I do see they offer a JS library I could utilize. I’ll definitely be looking into that!
As a result there is no LLM function calling currently and apps like LM Studio don’t support function calling when hosting models locally from what I remember. It’s definitely on my list to add the ability to retrieve outside data like searching the web and generating a response with the results etc…