Besides the ocr there appears to be all sorts of image-to-text metadata recorded, the nadella demo had the journalist supposedly doing a search and getting results with terms that were neither typed at the time nor appearing in the stored screenshots.
Also, I thought they might be doing something image-to-text-to-image-again related (which - I read somewhere - was what bing copilot did when you asked it to edit an image) to save space, instead of storing eleventy billion multimonitor screenshots forever.


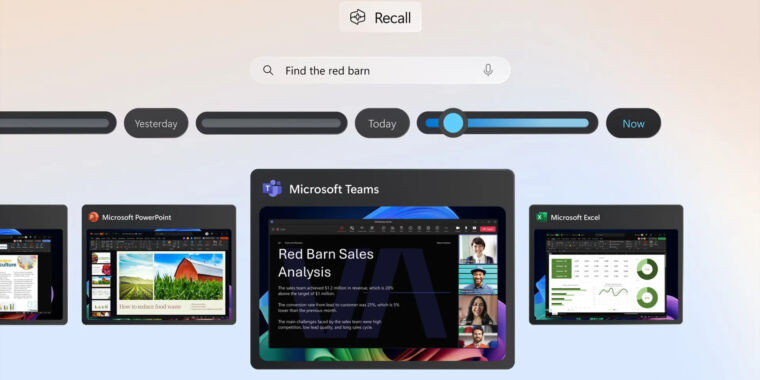
Besides the ocr there appears to be all sorts of image-to-text metadata recorded, the nadella demo had the journalist supposedly doing a search and getting results with terms that were neither typed at the time nor appearing in the stored screenshots.
Also, I thought they might be doing something image-to-text-to-image-again related (which - I read somewhere - was what bing copilot did when you asked it to edit an image) to save space, instead of storing eleventy billion multimonitor screenshots forever.
edit - in the demo the results included screens.